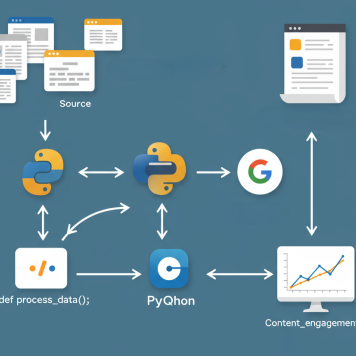
Analyzing Content Performance with Google Analytics and Python
Content performance analysis has always been a complex challenge for digital marketers and website owners. Over the years, I've experimented with various approaches—from combining entrance metrics across different mediums to calculating scroll rates, read times, and distinguishing between readers and scanners. Finding the right method to identify truly engaging content remains an ongoing pursuit.
A Fresh Approach to Content Analysis
Recently, I discovered an excellent content analysis methodology in a blog post by Simo Ahava and guest author Arben Kqiku, https://www.simoahava.com/analytics/content-analysis-using-ga4-bigquery-r-google-sheets-data-studio/. Their approach offers an elegant way to evaluate content performance by analyzing scroll depth patterns and correlating them with content length.
The original implementation was written in R, but I've converted it to Python to better suit my workflow and make it easier to customize for different client needs. In this article, I'll walk through my Python adaptation of their innovative approach.
The Python Implementation
The program consists of three main components that work together to analyze content performance. To download the complete Python Notebook - https://github.com/jaymurphy1997/content-performance-word-count/blob/main/notebooks/content_performance_word_count.ipynb
1. Building an English Dictionary
As Well as Loading Required Libraries
import pandas as pd
import requests
from bs4 import BeautifulSoup
import re
import gspread
from google.oauth2.service_account import Credentials
from gspread_dataframe import set_with_dataframe
def get_english_dictionary():
dict_url = "https://github.com/dwyl/english-words/raw/master/words_alpha.txt"
response = requests.get(dict_url)
words = set(word.strip().lower() for word in response.text.splitlines() if word.strip())
return wordsThis function downloads a comprehensive English dictionary from GitHub and stores it as a set. Using a set data structure is crucial here—it provides O(1) lookup time thanks to hash table implementation, making word verification extremely efficient when processing multiple pages.
2. Counting Words on Web Pages
def return_words(web_page):
"""Count English words on a web page."""
try:
# Fetch and parse the web page
response = requests.get(web_page)
soup = BeautifulSoup(response.text, 'html.parser')
# Extract text and clean it
text = soup.get_text()
text = text.lower()
text = re.sub(r'[",:.\\n]', '', text)
# Split into words and count those in the dictionary
page_words = text.split()
english_count = sum(1 for word in page_words if word in english_dictionary)
return english_count
except:
return 0This function:
- Fetches the HTML content from each URL
- Extracts all text using BeautifulSoup
- Cleans the text by removing punctuation and converting to lowercase
- Counts only legitimate English words (filtering out code snippets, random strings, etc.)
3. Main Processing Function
def main():
"""Main function to process URLs and update Google Sheet."""
# Set up Google Sheets authentication
scopes = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'
]
credentials = Credentials.from_service_account_file(
'credentials.json',
scopes=scopes
)
gc = gspread.authorize(credentials)
# Open the sheet
sheet_url = 'https://docs.google.com/spreadsheets/d/myspreadsheetsid/edit?usp=sharing'
spreadsheet = gc.open_by_url(sheet_url)
# Read data from the sheet
worksheet = spreadsheet.sheet1
page_data = pd.DataFrame(worksheet.get_all_records())
# Get English dictionary
global english_dictionary
english_dictionary = get_english_dictionary()
# Process each URL and count words
page_data['words'] = page_data['page_location'].apply(return_words)
# Write results to a new sheet
try:
output_sheet = spreadsheet.worksheet('output')
except:
output_sheet = spreadsheet.add_worksheet(title='output', rows=100, cols=20)
set_with_dataframe(output_sheet, page_data)
print("Processing complete. Results written to 'output' sheet.")
if __name__ == "__main__":
main()Setting Up the System
To use this script, you'll need to:
- Create a Google Cloud Service Account: This provides programmatic access to Google Sheets
- Download credentials.json: Your authentication file from Google Cloud Console
- Prepare your Google Sheet: Create a sheet with a column named 'page_location' containing your URLs
- Install required packages: pandas, requests, beautifulsoup4, gspread, google-auth, gspread-dataframe
Getting Started
I recommend testing with a small spreadsheet (10-20 URLs) initially to ensure everything is configured correctly. The script will:
- Read URLs from your Google Sheet
- Count English words on each page
- Create an 'output' tab with the results
Looking Forward
While this word-counting approach provides valuable insights into content length and complexity, content performance analysis remains a multifaceted challenge. I'm always interested in learning about other methodologies—whether you're using engagement metrics, conversion tracking, or novel approaches to understanding content effectiveness.
What methods have you found most effective for evaluating content performance on your websites? I'd love to hear about your experiences and insights in the comments below.
Special thanks to Arben Kqiku and Simo Ahava for their original article that inspired this Python adaptation.




0 Comments: